Start / Artiklar / Varför XML?
Gustaf Liljegren <gustaf.liljegren@xml.se>
Den här artikeln försöker svara på frågan om vilken roll XML har och varför det behövs. Vi börjar med att titta på ett par av dagens i särklass vanligaste sätt att lagra elektroniska dokument: Microsoft Word och HTML. Word får här symbolisera en mängd så kallade proprietära (ägda) filformat, medan HTML symboliserar ett öppet och "icke-kommersiellt" format som dessutom har stora likheter med XML. Artikeln avslutas med en kort introduktion till XML-formatet. Utformning, länkar och annat som ligger utanför XML 1.0 behandlas inte här.
1 Sammansatta dokument
1.1 Kompatibilitet
1.2 Filstorlek
1.3 Konverteringar
2 HTML
2.1 Bakgrund
2.2 Begränsningar på webben idag
3 XML
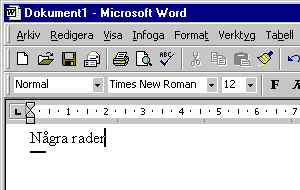
Olika slags filer lagrar samma information på olika sätt. Man säger att filerna lagras i olika "format". Ett vanligt filformat är textdokument från Microsoft Word. Samma dokument kan se precis likadant ut i Adobe Acrobat eller Internet Explorer, fast filen själv är i ett annat format. Det här illustreras bäst med några exempel. Jag öppnar Microsoft Word och skriver några rader:
Jag sparar, stänger filen och öppnar den igen. När filen öppnas i dess rätta miljö (i det här fallet Microsoft Word) ser vi filen som den tolkas av ordbehandlaren - inte som den egentligen ser ut. När jag öppnar filen i en helt naturell miljö visar det sig att den ser ut så här:
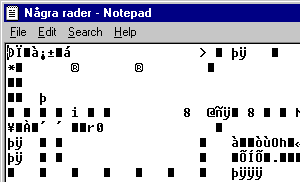
Microsoft Word, liksom många andra populära dokumentformat, lagrar inte bara den information vi matar in, utan också information om marginaler, typsnitt, författare, versionsnummer, standardskrivare och så vidare. Dessutom bakar man in eventuella bilder och tabeller i samma fil. Fördelen är att dokumentet, precis som ett pappersdokument, fungerar som en enhet som är lätt att hantera och flytta på.
Väldigt ofta är det så att en fil bara går att läsa i det program som skapade filen. Det behöver inte vara ett problem, men det finns många fall där man gärna vill kunna komma åt filen från andra program. Om programmet använder sitt eget filformat (som i exemplet ovan) måste två kriterier uppfyllas för att informationen ska vara åtkomlig:
Olika operativsystem, olika program och till och med olika versioner av samma program ställer dagligen till problem för alla som utbyter datorlagrade dokument. Ett annat vanligt scenario är att man behöver något från en gammal fil, men programmet som skapade filen används inte längre. Informationen blir oåtkomlig på bara några år.
Texten "några rader" i exemplet ovan är 11 tecken långt. Det är 11 bytes om jag skulle sparat den i en enkel texteditor (till exempel Anteckningar i Windows) . När jag sparar filen i Word blir den drygt 19,000 bytes. Behöver vi all kringliggande information om dokumentets egenskaper och utformning? Ibland gör vi det, men långt ifrån alltid och som vi ska se finns det andra, betydligt utrymmessnålare och smartare sätt att lagra den omkringliggande informationen.
Datorlagrad information har en kort livslängd som förr eller senare slutar på ett av två sätt: endera konverteras informationen till ett modernare format, eller så kasseras den. Konvertering är en kostsam process som aldrig ger ett perfekt resultat, och därför konverterar man bara information man använder, och mer sällan arkivmaterial. För varje uppgradering av programvaran i en stor organisation "försvinner" därför mängder med information.
Vissa program har funktioner för konvertering (överföring) av information från olika format. Man gör så bland annat för att fästa köparna vid sin egen produkt. Det ska vara lätt att byta till produkten, men svårare att byta från den. Ibland förhindrar man andra att göra samma sak genom att hålla det sätt på vilket man lagrar informationen hemligt.
I exemplet såg vi att information ibland lagras på ett för människor oläsbart sätt. Utan urspungsprogrammet är det praktiskt taget omöjligt att vaska ut informationen och överföra den till tidsenliga format när det blir nödvändigt. Nu ska vi titta närmare på ett annat filformat som lagrar filer som är läsbara överallt, även utanför sin naturliga miljö.
HyperText Markup Languge (HTML) är en av grundpelarna i det världsomspännande nät av ihoplänkade elektroniska dokument som i folkmun kallas "webben". HTML är det filformat som används för att lagra alla webbsidor. Till skillnad från Word är det inte ett sammansatt filformat - såväl bilder som utformning lagras i separata filer. HTML lagrar istället beskrivande instruktioner om vad varje informationsfragment är: en huvudrubrik, en tabell, en lista, ett stycke och så vidare. Så här kan det se ut:
<html>
<head>
<title>Exempel på HTML</title>
</head>
<body>
<h1>Exempel på HTML</h1>
<p>Överallt i företag, myndigheter och andra organisationer
skapas och lagras det stora mängder information. Den mesta
informationen finns på papper, men det blir allt vanligare att
lagra information i ett dataformat där den blir lättare
tillgänglig och kan återanvändas på olika sätt.</p>
<h2>Nu kommer en lista</h2>
<ul>
<li>Första elementet</li>
<li>Andra elementet</li>
<li>Tredje...</li>
</ul>
</body>
</html>
Vissa ord är inkapslade inom < och >. De kallas element eller i dagligt tal "taggar", och är instruktioner till det program (oftast en webbläsare) som ska visa filen. Elementen har oftast en starttagg och en sluttagg som tillsammans kapslar in valda delar av dokumentet. I exemplet ovan kapslas rubriken "Exempel på HTML" in av starttaggen <h1> och sluttaggen </h1> (elementet <h1> är HTML:s sätt att uttrycka att texten är en huvudrubrik).
På detta sätt får delarna en innebörd för webbläsaren, utan att taggarna går närmare in på hur delarna ska presenteras. Taggarna anger att "Exempel på HTML" är en huvudrubrik, och Microsoft Internet Explorer tolkar det som Times, 24 punkter, fet. I ett annat sammanhang (på en monokrom skärm, i talsyntes eller blindskrift), skulle <h1> kunna tolkas på ett annat sätt. Elementet är bara en abstraktion av begreppet "huvudrubrik", och varje mjukvara måste kunna välja sitt eget sätt att uttrycka att det rör sig om en rubrik. Så här visas filen i Internet Explorer:
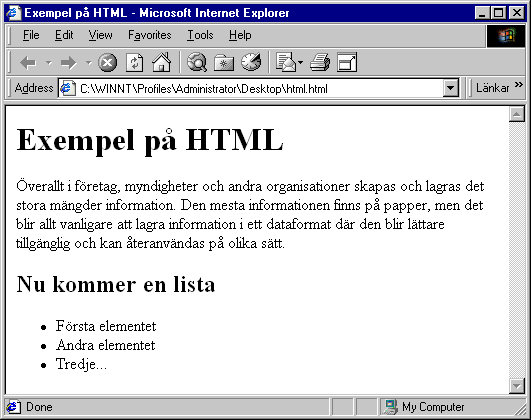
Taggarna försvinner i webbläsaren, och kvar blir själva informationen vi vill se. Webbläsaren följer också våra föreställningar om hur rubriker, stycken och listor ska se ut. Vi förväntar oss till exempel att en rubrik ska vara större än brödtexten och gärna framhävd i fetare stil.
Man kan med detta säga att HTML är ett presentationsinriktat filformat, men presentationen beror på mjukvaran och inte på taggarna. Endast i enstaka fall beskriver HTML utformning, som i elementen <b> (fet) och <i> (kursiv), som följt med ända från början. I andra fall rekommenderas det att man använder en så kallad stilmall i en fil vid sidan om, för att beskriva hur varje slags element ska visas i webbläsaren eller i andra applikationer.
HTML är ett relativt säkert format att arkivera och överföra dokument i. Man kan öppna filerna på vilken dator som helst och läsa rakt av, även om man inte har en webbläsare. Konverteringar från HTML underlättas dessutom av att informationen är strukturerad och till viss del definierad med hjälp av taggarna. Dessutom är det utrymmessnålt - filen vi tittat på är bara 571 bytes.
HTML föddes i början av 1990-talet ur behovet av ett universiellt format för att överföra vetenskapliga dokument i ett nätverk av i huvudsak universitet och högskolor. Man sökte ett filformat som inte var beroende av ett speciellt operativsystem eller program. Det skulle vara läs- och skrivbart för människor, och dessutom skulle det vara lätt att lära.
Man hämtade syntaxen från en av samtidens stora innovationer - Standard Generalized Markup Language (SGML), som används till att skapa standardiserade och för människor läsbara filformat med en speciell syntax som tillåter en mängd olika tillämpningar. SGML bygger bland annat på principen att skilja utformning från innehåll för att på så sätt möjliggöra att samma information kan användas i flera olika sammanhang. HTML, som bara är en av många tillämpningar av SGML, blev snart så populärt att det idag tillräknas långt större betydelse än SGML självt.
HTML byggdes på dokumentens minsta gemensamma nämnare. Alla dokument hade i grund och botten samma logiska delar: rubriker, stycken, tabeller och så vidare. Man gjorde element för vart och ett av dem, man gjorde programvara som kunde tolka dem och man byggde in en speciell funktion för att förflytta sig från ett dokument till ett annat.
När webben tog fart föddes nya behov. Det var inte längre bara studenter och professorer som använde nätet. Företag, journalister och privatpersoner tog över, gav sina bidrag och gjorde webben till en mänskligare plats. Problemet var att HTML bara dög just till att definiera och strukturera delar av ett typiskt textdokument. Resultatet blev att webben mest av allt liknade en elektronisk bok, eller som någon sa: "en hög med böcker på golvet, istället för ett elektroniskt bibliotek".
Nu ville man att webben skulle bli mer dynamisk, inte statisk som en bok. Man hittade på ett nytt ord: interaktivitet. Det kanske äldsta exemplet på interaktivitet på webben är söktjänster som AltaVista och Yahoo. Man fyller i ett elektroniskt formulär och får en lista på träffar; oftast tillsammans med en mängd orelaterade dokument. Anledningen till den dåliga precisionen är att HTML bara kan beskriva typiska dokumentdelar, inte skilja en siffra från en bokstav, ett namn från ett ord eller ett brev från en faktura. Ord kan också ha flera betydelser. Gandhi är inte bara en historisk person, utan också en författare. Ek är både ett namn på ett träd och ett efternamn. Hur ska vi får datorer att förstå det?
Som människor besitter vi kunskap och tolkningsförmåga som datorer saknar. Likväl behövs dessa egenskaper för att kunna skapa interaktiva tjänster som kan hämta fram just det som vi vill ha. Lösningen är inte att ge HTML nya element som "efternamn", "tillverkningsår" eller "densitet". Om man sammanförde önskemål från alla vetenskaper och branscher skulle det behövas tusentals element, och HTML skulle bli oöverskådligt och oanvändbart.
Lösningen finner vi snarare hos SGML: varje tillämpning kräver sin egen uppsättning av element. Precis som HTML utvecklades från SGML, kan vi från SGML också skapa andra språk med sina egna uppsättningar av element - så kallade dokumenttyper. Problemet är bara att SGML är mer avsett för informationslagring än för det informationsutbyte som dagens webbtillämpningar kräver. SGML är mer avancerat än nöden kräver och därför svårt att bygga mjukvara till. HTML fick sin spridning just för att man i mjukvaran kunde bortse från SGML och bara bygga in det som behövdes för att presentera informationen.

Handel på webben hämmas av otillräckliga standarder.
Inom vissa verksamhetskritiska områden går tjänsterna
inte att utveckla vidare med dagens teknik.
Ibland är det inte bara tjänsten som behöver vara dynamisk, även viss typ av information kan behöva uppdateras löpande (aktiekurser och väder är två exempel). HTML är dåligt anpassat för dynamisk information. Det är ineffektivt att lagra informationen i en dokumenttyp som HTML när den behöver ändras hela tiden. Istället lagrar man informationen i databaser och konverterar den med automatik när någon begär den från en webbsida.
Det finns mängder av tjänster på webben idag som fungerar efter denna princip - en databas kopplad till en webbsida, ibland med ett formulär för användaren att fylla i. Fastän det fungerar bra har man i vissa sammanhang inom till exempel handel, banker och spel uppnått en kritisk punkt där det inte går att komma längre. Den platta och låsta strukturen i databaser och trubbigheten hos HTML gör omvägarna allt mer komplexa. I vissa fall har komplexiteten blivit så stor att man tvingas ställa krav på användarnas webbläsare.
Den typiska tvådimensionella tabellformen i en databas är för platt för att lagra strukturen i viss information. Dessutom är strukturen inte utvidgningsbar när den väl definierats: varje post (rad) i tabellen har sin uppsättning fält (kolumner) för olika uppgifter, och varje post måste ha precis samma uppsättning fält. Databaser är inte heller läsbara filer eller öppna standarder; olika databasformat är därför inkompatibla med varandra.
En viktig felkälla är också konverteringarna mellan olika format på vägen till publicering. Informationen skrivs kanske i ett vanligt ordbehandlingsprogram, för att sedan konverteras till något databasformat och slutligen till HTML när någon begär den. Det vore enklare om människor och datorer kunde använda sig av samma filformat hela vägen från inmatning till publicering och vidare till arkivering.
Extensible Markup Language (XML) heter den nya webbstandard som är på väg att lösa alla ovan nämnda problem. Det är en för webben framtagen delmängd av SGML - det vill säga en förenklad specifikation på hur man definierar dokumenttyper. Ordet "extensible" kommer av att man till skillnad från HTML kan använda sina egna elementnamn, vilka man (om man vill) kan använda mer strikt som en separat dokumenttyp (som HTML). I HTML saknar vi till exempel elementet "efternamn". Anta att vi med datorns hjälp vill kunna automatisera en viss process där datorn måste kunna skilja efternamn från andra ord. Om alla efternamn är inkapslade av elementet "efternamn" är det inga problem:
<efternamn>Abrahamsson</efternamn>
Med denna information vet datorn att "Abrahamsson" är ett efternamn och inte vilket ord som helst. Informationen kan datorn sedan använda på ett oändligt antal sätt: den kan hämta ut alla efternamn ur en familjekrönika, den kan skriva alla efternamn i rött, den kan använda efternamnet som en del av ett helt nytt dokument: ett recept för apoteket, en biljett till något evenemang eller ett register över tidningsprenumeranter. De beskrivande "taggar" som omger namnet Abrahamnson gör att datorn kan hantera namnet på ett för människor intelligent sätt. XML ger datorn nya möjligheter att sortera ut och hantera precis den information vi frågat efter.
Ett fullständigt dokument kan se ut som följer:
<?xml version="1.0" encoding="iso-8859-1"?>
<visitkort>
<namn>Gustaf Liljegren</namn>
<titel>Webbutvecklare</titel>
<företag>XML Sweden AB</företag>
<adress>
<box>Box 2124</box>
<postnummer>176 02</postnummer>
<postort>Järfälla</postort>
</adress>
<telefon>08-58355383</telefon>
<fax>08-58355787</fax>
<hemsida>www.xml.se</hemsida>
<e-post>gustaf.liljegren@xml.se</e-post>
</visitkort>
Det här exemplet är betydligt mer avancerat, men även en person utan datorbakgrund förstår lätt innebörden i det. Den här enkelheten är något helt unikt i datorvärlden och något som framtida arkeologer eller främlingar från andra planeter kommer att tacka oss för.
Med XML struktureras informationen på ett sätt som gör den lättare att finna. I exemplet ovan används elementet <adress> till att kapsla in en ordinär adress. "Box", "postnummer" och "postort" är alla logiska delar av begreppet "adress". De separeras här för att göra det möjligt för en dator att exponera dem eller på annat sätt bearbeta dem en och en. Samma adress hade i HTML vanligen skrivits på detta sätt:
<p>Box 2124<br>176 02<br>Järfälla</p>
I bästa fall kan datorn tolka den här meningen som "ett stycke text med två radbrytningar". Datorn har däremot ingen chans att förstå att det rör sig om en adress, eller vad som är vad i adressen.
Lagringen i XML ger oss på sikt ett nytt sätt att se på datorlagrade dokument. Det är inte längre dokumenten som är den minsta instansen av information: med XML-dokument blir den minsta instansen varje liten datamängd inuti dokumenten, som till exempel "postort" eller "efternamn". Datorer kan gå rakt in i dokumenten och hämta fram precis de uppgifter vi frågat efter.
För informationsutbyte är XML ett ideal. Den enkla syntaxen kan beskriva allt från traditionella textdokument till databasliknande information. XML är på grund av detta intressant för överföringar från olika databasformat, men också som ett databasformat i sig. Genom XML kommer information att kunna hanteras mellan olika system och program utan någon konvertering.
Allt detta vilar på många års erfarenhet av SGML. Man kan säga att XML är kontentan av SGML efter drygt 10 års användning. Dessutom är XML en startpunkt för nya standarder som ska lösa kraven från webben och andra miljöer där information lagras och utbyts.
Copyright © 2002, AB XML Sweden (info@xml.se)
Webmaster (webmaster@xml.se)